CEO Александр Горник рассказал, как попробовали полную автономию команд и централизацию, роняли надежность, демотивировали команды, как в результате с этим справились и выработали свою систему масштабирования.
7 июня 2021
Как масштабируем разработку и улучшаем надежность
Если бизнес идет вверх, то запросы и нагрузка на разработку увеличиваются в разы. Рано или поздно каждый управленец сталкивается с выбором из двух крайностей: встать на сторону бизнеса, двигать продукт и демотивировать разработчиков бесконечным техдолгом или дать свободу разработке и потерять контроль над задачами бизнеса.
Mindbox 15 лет развивает B2B-продукт и вырос с 3 до 70 человек в разработке. Мы тестировали разные подходы к масштабированию и готовы поделиться опытом, чтобы вам не пришлось наступать на те же грабли. Ниже расскажу, как попробовали полную автономию команд и централизацию, роняли надежность, демотивировали команды, как в результате с этим справились и выработали свою систему масштабирования.
По материалам выступления на Agile Days 2021:
Надежность как ядро разработки
Чтобы оценить, о каких масштабах разработки и нагрузке пойдет речь, расскажу о размере компании.
В Mindbox одна из самых нагруженных разработок в России, но при этом она сохраняет высокую надежность. Когда покупатель пробивает чек на кассе в «Бургер Кинге» или аптеке «Ригла», транзакция идет к нам. За 200 миллисекунд мы рассчитываем суммы и отвечаем кассе. Если сервис упал, то много людей по всей стране 24/ 7 становятся несчастны.
За последние 3–4 года бизнес растет по 40–50% в год и нагрузка удваивается ежегодно. Внешне всё отлично, но у Mindbox был длинный период становления, который влиял на масштабирование разработки.
Масштаб бизнеса и разработки

Эволюция разработки

Как работает автономия и централизация разработки
Проблема масштабирования разработки сводится к поиску баланса между автономией и централизацией. Есть две организационные крайности:
- Автономия. Во многих компаниях победили автономные инженеры и нет никаких сроков. Разработка постоянно закрывает секретный техдолг, а бизнес не понимает, как решать крупные задачи. Это заканчивается революцией: бизнес теряет терпение и вносит радикальные изменения в процессы.
- Централизация. Другая крайность — когда побеждает бизнес. Дедлайны спускаются на разработку сверху, задачи бизнеса решаются, но копится техдолг. Потом процессы опять замедляются и история заканчивается революцией: предлагают переписать код с нуля или продать компанию.
Микросервис и монолит. Две архитектурные крайности — микросервис и монолит — напрямую не связаны с описанными типами управления, но похожи по эффекту. Микросервисы работают быстро, но чем их больше, тем больше инфраструктурных задач реализуются несколько раз вместо одного. В монолите, наоборот, сначала всё эффективно, но потом замедляется из-за множества зависимостей.
Мы нашли баланс между автономией и централизацией: дали техническую автономию продуктовым командам в вопросах сервисов и централизовали управление процессами, которые относятся ко всем командам. Ниже расскажем, что это означает и как мы к этому пришли.
Как внедрили автономию
С 2007 по 2013 год было мало клиентов и бизнес рос медленно, потому что писали большой и сложный продукт. При этом управление разработкой было простым: один главный бизнес-эксперт и главный архитектор — это я — и 3–4 команды. Делал статусы раз в неделю, потом раз в две недели ходил по командам — эффективно и легко.
Дали автономию командам. Постепенно бизнес стал прибавлять по 40–50% в год, поэтому нужно было запускать больше продуктов и продвигаться быстрее. В то же время мы начали строить бирюзовую культуру, прочитали книгу Лалу и решили, что нужны автономные продуктовые команды с менеджерами продуктов. И это заработало — запустили новые продукты.
Децентрализовали инфраструктуру. Мы решили, что раз такой подход работает, надо его распространять дальше. Была команда супергероев — топовые инженеры, которые поддерживали продакшен и работали над сложными задачами. Чтобы разработка стала ещё быстрее, выделили каждой команде своего эксперта по инфраструктуре, а централизованную инфраструктурную команду разделили на две продуктовые. И это тоже сработало, разработка продуктов ускорилась.
Уронили надежность. Потом появились нюансы. Большинство наших клиентов из e-commerce, поэтому проводят «черную пятницу» — большую распродажу в конце года, когда у нагрузки пиковое значение. Кроме этого, нагрузка ещё и удваивалась каждый год. В такую «черную пятницу» сервис упал.
Всё лежит и всё плохо, чрезвычайная ситуация. Провели спринт надежности и полностью остановили roadmap, чтобы вернуть сервис к жизни. В книгах о самоуправлении это называют «остановить конвейер», когда все команды бросаются чинить надежность. И мы остановили, но никто не побежал чинить, потому что половина людей не понимала, в чем проблема и куда бежать. Это было первое наблюдение, а потом надежность в целом стала резко ухудшаться.
Как внедрили централизацию
Централизовали управление. Прочитали книгу про LeSS (Large Scale Scrum), сходили на тренинг и решили централизовать разработку: внедрить общий roadmap, единое управление и разгрумить эпик надежности.
В результате немного улучшили надежность и roadmap начал продвигаться. Мы разделили его на большие куски, установили очередность продуктов и работали над ними силами всех шести команд.
Внедрили LeSS и роль CTO. Надежность разово починили, но остался монолит на 2 миллиона строк кода. Несмотря на то что мы централизованно внедрили roadmap и в каждой команде работали эксперты по инфраструктуре, техдолг и проблема корневой надежности децентрализованно не решались.
Так мы создали роль CTO (chief technical officer), хотя до этого не было менеджмента, отвели 30% ресурса на техдолг и внедрили LeSS. Это значит, что 70% разработчиков занимались roadmap бизнеса, а 30% — техническим roadmap, который определяет CTO. В результате техдолг начал сокращаться, и мы увидели положительные изменения.
Создали ритуал надежности. CTO предложил, чтобы команды сами приходили и рассказывали, что и почему они сделали или планируют сделать для надежности. Так появился ритуал надежности. Архитекторы со всех команд, CTO и продуктовые эксперты собирались раз в две недели или раз в месяц и разбирали, какие выявились дефекты и критические баги, в чем была причина и что нужно чинить на глобальном уровне, а что решать локально. Так мы ввели разумное регулирование и децентрализация заработала.
Демотивировали инженеров и менеджеров по продукту. Следом случилась ещё одна «черная пятница», и сервис снова лег. Это было грустно, хотя мы уже видели, что есть положительные изменения. Но это было не главным.
Главное, что год мы прожили в режиме LeSS и заметили негативные эффекты для компании. Инженеры и менеджеры по продукту были демотивированы. У инженеров не было домена и чувства собственности, как у в автономных команд: три месяца они работали над одним продуктом, потом три месяца над другим. Менеджеры по продукту загрустили, потому что roadmap планируется централизованно и time to market стал огромным. Нельзя было взять и внедрить небольшую доработку для клиента, потому что roadmap управляют централизованно.
Как нашли баланс между автономией и централизацией
Вернули командам автономию. Мы увидели, что регулируемая децентрализация работает для повышения надежности, поэтому решили вернуться к истокам, свернуть LeSS и разделить продуктовые команды.
Вернули команду инфраструктурной платформы. Фактически инфраструктура — это тоже внутренний продукт, а CTO выполняет роль менеджера по продукту, поэтому выделили отдельную команду под инфраструктуру.
С точки зрения «бирюзы» инфраструктурная команда казалась неправильным шагом, но в деле это показало себя хорошо, и такая команда мотивировала всех остальных. Сначала мы боялись, что интересные технические задачи уйдут в инфраструктурную команду. На самом деле выделили для этого отдельных экспертов и отдали задачи, которыми не хотели заниматься разработчики из других команд.
Оставили 30% ресурса команды на локальный техдолг. Мы договорились о двухуровневом разделении. На верхнем уровне 30% всего ресурса разработки отдали CTO на инфраструктурную команду и технический roadmap. Ещё 30% отдали на техдолг, который приоритезирует команда. Фактически с момента, когда начались проблемы с надежностью и масштабированием, почти 50% всего ресурса — это технические задачи.
Техдолг — ~30% платформы и 30% команды
около 50% в целом
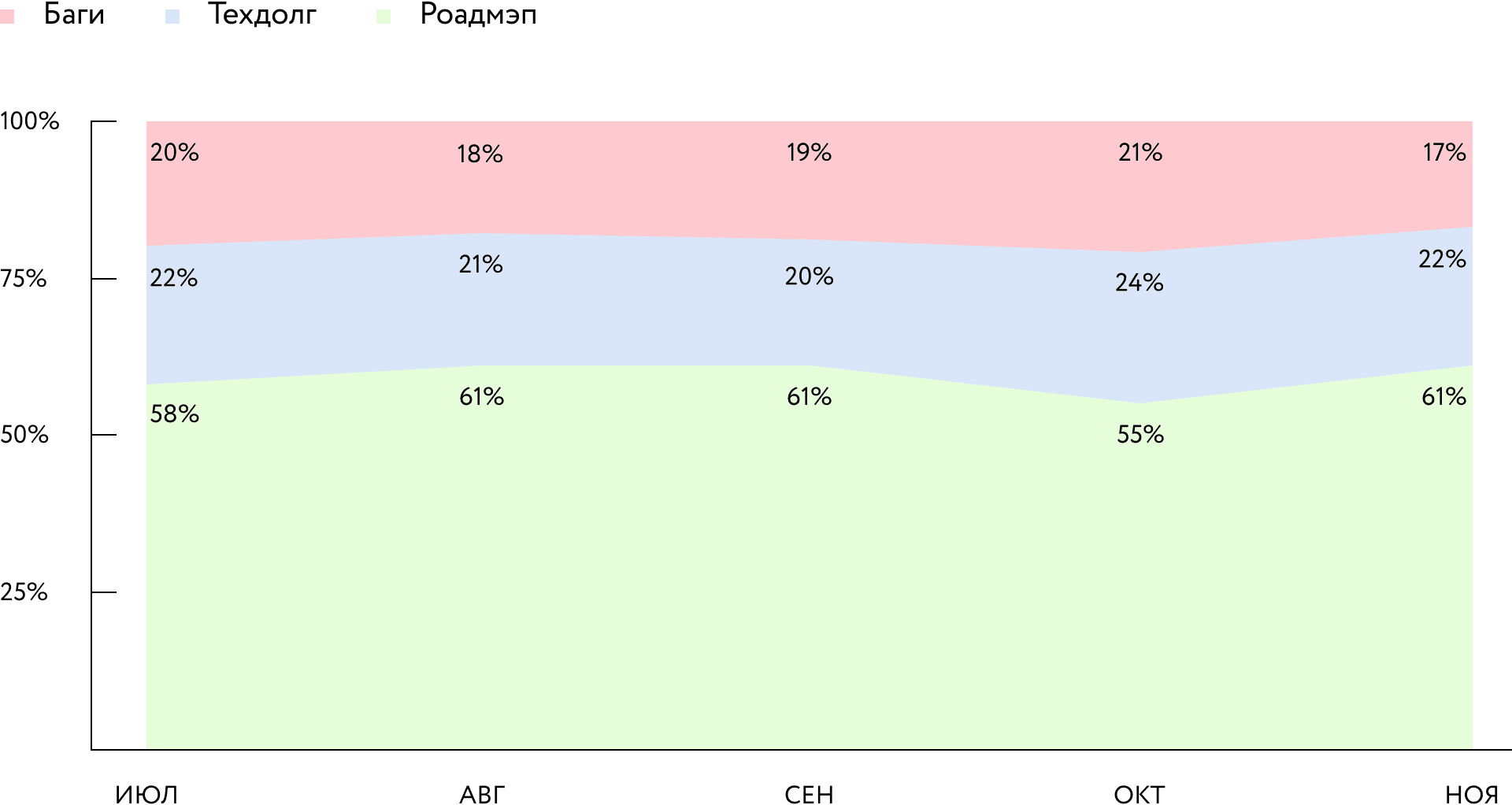
Внедрили кросс-командный рефайнмент. Это практика из LeSS, которую мы модифицировали. Прежде чем команда начинает работу над каким-то автономным эпиком, она готовит описание и выносит на обсуждение с другими командами. Такой подход помогает выявить риски и понять, как изменения касаются других команд и какие зависимости в монолите не учли.
Изначально ошибка была в том, что мы выделили автономных менеджеров по продукту, которые создавали интересные фичи, но при этом не были экспертами по надежности и инфраструктуре в монолите. И то, что они делали, ломало другие фичи из-за чрезмерной централизации. Чтобы снять эти риски, мы оставили кросс-командный рефайнмент.

Из LeSS оставили кросс-командный рефайнмент, чтобы снять риск монолита и управлять roadmap
Ввели автоматический контроль надежности. Чтобы усилить надежность, мы посоветовались с разными компаниями и сделали автоматическую метрику. Раньше клиенты жаловались на критические баги, менеджеры сообщали об этом разработке и мы их анализировали. А теперь мы создали автоматические уведомления, который приходят, если нарушаются определенные метрики. И это помогло улучшить надежность, потому что на всех статусах мы стали обсуждать формальные вопросы: нарушается SLA или нет.
Несмотря на то что в прошлый раз мы упали в «черную пятницу», было ощущение, что платформа стала надежнее и мы движемся в верном направлении. Новая метрика доказала наши наблюдения — надежность компании действительно росла.
Нарушения SLA среднего клиента в месяц — надежность повышается
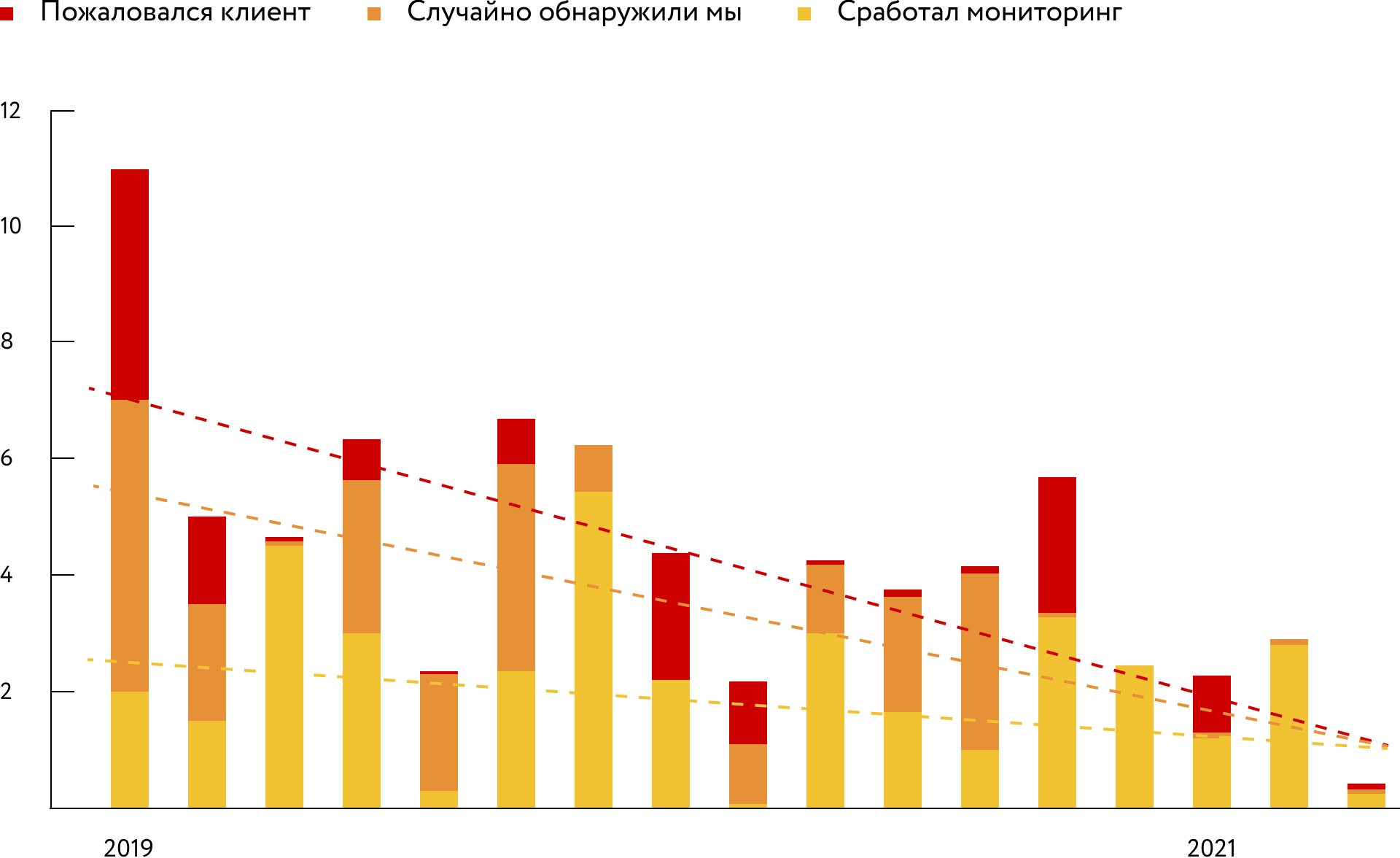
Починили надежность. Следующую «черную пятницу» мы пережили нормально. Это стало доказательством того, что процесс работает и есть положительный эффект для бизнеса.
Создали роль Scrum-мастера. После того как разобрались с рисками в децентрализованном roadmap, справились с техдолгом и надежностью, решили повышать эффективность разработки. Для этого создали роль Scrum-мастера, который собирает весь опыт разработки (developer experience) и заносит в специальную форму все препятствия и причины, мешающие разработке. Потом по аналогии со статусами по надежности Scrum-мастера централизованно обсуждают с CTO задачи за месяц, приоритезируют их и часть добавляют в техдолг.
Создали круги управления. Чтобы комплексно управлять общими аспектами разработки, мы организовали виртуальную команду, или круг управления, представители которого сидят в разных командах. У этого круга есть набор ритуалов, которые собраны на доске в Trello: встречи по бюджету, демонстрации продукта или найму. Такое кросс-командное общение помогает сфокусироваться на каждом процессе и на том, как его улучшить во всех командах сразу.
Виртуальная команда (круг) управления
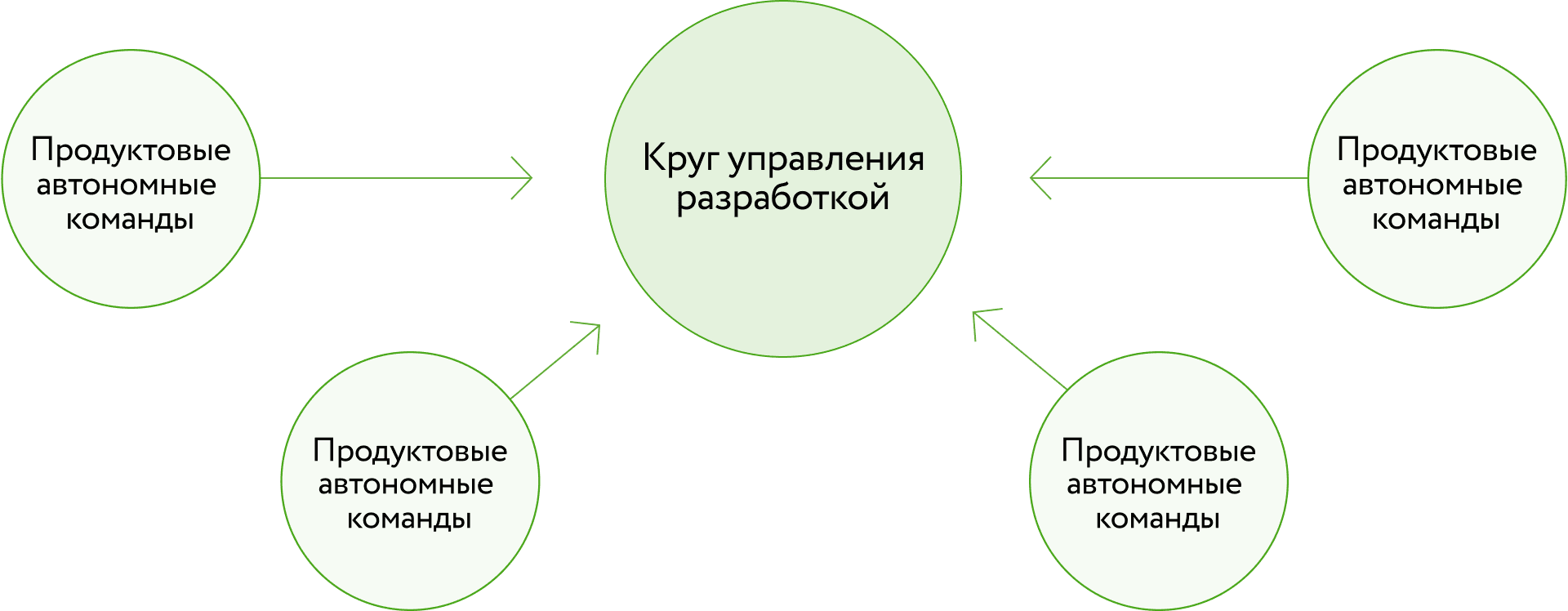
Ритуалы управления

Круг управления помогает аккумулировать кросс-командные аспекты: надежность, стоимость железа, найм, developer experience. Для этого проводятся встречи — ритуалы управления
Определили метрики разработки. Пока мы масштабировали разработку, нас волновал один вопрос: какие метрики позволяют оценить разработку и что нужно оптимизировать. Это было неочевидно.
Мы знали, что скорость и roadmap нельзя измерять, потому что есть проблемы с техдолгом и это только демотивирует разработчиков. На уровне стратегии разработки мы сформулировали, что цель разработки — оптимизировать непрерывный запуск продуктов (time to market) в рамках ограничений надежности, стоимости железа и без увеличения технического долга. И ровно такие же ожидания сформировали для команды. Команда должна непрерывно поставлять фичи, увеличивать time to market, но при этом поддерживать определенные обязательства по надежности, SLA и стоимости.
Когда мы сформулировали ожидания, стало легче оценивать результаты разработки. Исходя из этого мы строим метрики и продолжаем оптимизировать разработку.
Показатель эффективности
в рамках SLA, стоимости железа и без увеличения техдолга
Разработка
Команда
Непрерывный запуск и оптимизация time to market новых продуктов, которыми можно гордиться
Непрерывный релиз и оптимизация time to market инкрементов, которые принял клиент на продакшене
Какую выработали систему масштабирования разработки
Продуктовые команды. Если бы мы сейчас строили разработку с нуля, то по умолчанию выделили децентрализованные продуктовые команды. Желательно, чтобы у каждой был свой сервис и не было монолита на несколько команд. Наша реальная ситуация оказалась сложнее: есть монолит, поэтому надежность зависит от него, есть централизованный найм и централизованная стоимость облачного железа.
Разумное регулирование общего. Как ядро оставили общие задачи, над которыми должны работать централизованно: roadmap монолита, надежность и инфраструктура, стоимость железа и developer experience. Если нет общих знаний о том, как создаются базовые вещи, то перемещение разработчиков между командами будет затруднено, код будет дублироваться и есть риск потерять эффект масштабной разработки, когда каждая команда существует изолированно от всех.

